随着企业对系统稳定性和实时响应的需求日益增长,搭建一套高效的服务监控和告警系统变得至关重要。本文将引导您快速入门如何搭建服务监控各插件,并集成企业微信告警功能,帮助您构建基础软件服务监控体系。
一、服务监控基础概念与准备
在开始搭建前,我们需要理解服务监控的核心目的:实时检测服务运行状态、收集关键指标(如CPU、内存、磁盘使用率),并在异常时及时告警。常用监控工具包括Prometheus、Zabbix或Grafana等开源软件。建议选择Prometheus作为核心监控系统,因其轻量、易扩展,并支持丰富的插件。
准备工作:
- 环境要求:一台或多台Linux服务器(如Ubuntu或CentOS)。
- 安装基础依赖:确保系统已安装Docker或直接安装相关软件包,以简化部署过程。
二、搭建服务监控系统
- 安装和配置Prometheus:
- 使用Docker快速部署:执行
docker run -d -p 9090:9090 prom/prometheus启动Prometheus服务。
- 配置监控目标:编辑Prometheus配置文件(prometheus.yml),添加需要监控的服务地址,例如应用服务器、数据库等。
- 集成监控插件:
- Node Exporter:用于收集服务器硬件和系统指标。通过Docker运行:
docker run -d -p 9100:9100 prom/node-exporter。
- 其他插件:根据服务类型,可选cAdvisor(容器监控)或Blackbox Exporter(网络探测)。在Prometheus配置中添加对应的job,以拉取数据。
- 可视化监控数据:
- 安装Grafana:使用Docker启动:
docker run -d -p 3000:3000 grafana/grafana。
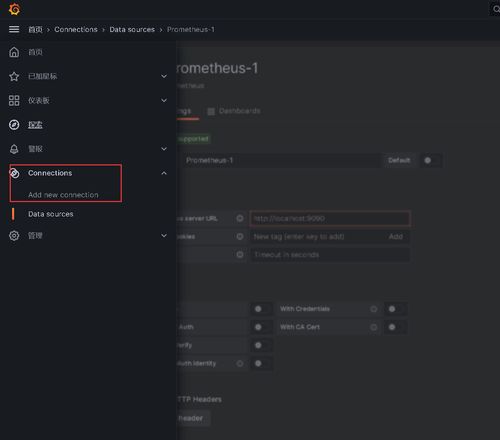
- 连接数据源:在Grafana中添加Prometheus作为数据源,然后导入预设仪表盘(如Node Exporter Full),实时查看指标图表。
三、集成企业微信告警功能
企业微信告警能确保团队在服务异常时及时接收通知。以下是实现步骤:
- 配置Alertmanager:
- Alertmanager是Prometheus的告警管理组件。使用Docker部署:
docker run -d -p 9093:9093 prom/alertmanager。
- 创建告警规则:在Prometheus配置中定义规则文件(例如alerts.yml),设置阈值(如CPU使用率超过80%触发告警)。
- 设置企业微信机器人:
- 在企业微信中创建一个群聊,添加“群机器人”,获取Webhook URL。
- 配置Alertmanager与Webhook集成:编辑Alertmanager配置文件(alertmanager.yml),添加企业微信的Webhook接收器,指定告警消息格式。
- 测试告警流程:
- 模拟服务异常(如停止一个监控服务),检查Prometheus是否触发告警,并通过Alertmanager发送消息到企业微信。确保团队成员能收到通知。
四、优化与扩展建议
- 安全性:使用TLS加密监控数据传输,并设置访问控制。
- 高可用性:部署多个Prometheus实例,并配置集群模式。
- 自定义指标:根据业务需求,开发自定义Exporter,监控特定应用。
通过以上步骤,您可以快速搭建一个基础的服务监控和告警系统。这不仅提升了运维效率,还能在问题发生前预警,保障服务稳定性。随着业务扩展,可进一步探索更高级功能,如自动化修复或集成其他通知渠道。持续监控和优化将助您构建更可靠的基础软件服务。